Mi hijo me pidió que le arme un blog, como me gusta complicar las cosas, esto me llevó a revivir una vieja raspberry que tenía problemas con el voltaje y por lo tanto no estaba usando, y aprovechando unos días de vacaciones, me puse a trabajar (era el cable el problema, y no la placa como alguna vez pensé).
Durante muchos años tuve este blog en linea corriendo en su propio hardware, en ese momento me parecía buena idea mantenerme con la arquitectura ARM v7 (32 bits) ya que era lo mas popular por fuera del mundo intel/amd, pero siendo que estamos en 2023, cobra sentido montar algo utilizando una arquitectura acorde a los tiempos que vivimos, y decidí armar una imagen ARM v8 (64 bits).

Hace varios años había armado con un gran amigo a Ñamandú, una solución que por lo divertido que estuvimos los últimos tres años no hemos vuelto a tocar, al medio era obvio que alguna solución iba a aparecer y que el costo de actualizar lo que habíamos hecho iba a ser superior a adaptar algo ya existente, es por eso que me puse a ver tekton y a retomar las pruebas de multiarch building en el universo de buildah.

Escapa al objetivo de este texto cubrir los fundamentos de tekton, que se pueden encontrar en la documentación oficial, me voy a enfocar en dejarme documentado para mi yo del futuro, las modificaciones que tuve que realizar sobre la task de buildah oficial
Lo primero fue entender cuáles eran los comandos necesarios para hacer un build con buildah, generando un manifiesto mutliarquitectura, subiéndolo luego junto con las imágenes resultantes a un registro.
Modificaciones en la task
Dentro del script de la task, lo primero que hice fue agregar una configuración en /etc/containers/registries.conf que permitiese buscar imágenes en el registry de docker (docker.io), de esta forma si queremos buildear imágenes con referencias del tipo FROM alpine:latest no tendremos que modificarlas a algo como FROM docker.io/alpine:latest, como la idea es buildear imágenes de terceros, esto nos puede ser de mucha utilidad.
echo 'unqualified-search-registries = ["docker.io"]' >> /etc/containers/registries.conf
Luego, le agrego al script la creación de un manifest, utilizando buildah manifest create multiarchmanifest (el nombre del manifest no me importa, ya que lo uso temporalmente durante el tiempo de vida de la ejecución del pipeline).
Posteriormente, modifico la linea de buildah bud para incluir el uso del manifest creado:
buildah ${CERT_DIR_FLAG} --storage-driver=$(params.STORAGE_DRIVER) bud \
$(params.BUILD_EXTRA_ARGS) --format=$(params.FORMAT) --manifest multiarchmanifest \
--tls-verify=$(params.TLSVERIFY) --no-cache \
-f $(params.DOCKERFILE) -t $(params.IMAGE):$(params.TAG) $(params.CONTEXT)
Luego reemplazo la linea de push (en el archivo final dejo los comments para que se entienda dónde fue el reemplazo), por un buildah manifest push
buildah ${CERT_DIR_FLAG} --storage-driver=$(params.STORAGE_DRIVER) manifest push \
$(params.PUSH_EXTRA_ARGS) --tls-verify=$(params.TLSVERIFY) \
--digestfile /tmp/image-digest --rm multiarchmanifest \
--format=$(params.FORMAT) docker://$(params.IMAGE):$(params.TAG)
También agregué un parámetro TAG a la tarea, de forma tal de que pueda luego definir en el pipelinerun el tag multiarch que quiero construir.
El archivo resultante queda entonces definido como:
---
apiVersion: tekton.dev/v1beta1
kind: Task
metadata:
name: buildah
labels:
app.kubernetes.io/version: "0.5"
annotations:
tekton.dev/categories: Image Build
tekton.dev/pipelines.minVersion: "0.17.0"
tekton.dev/tags: image-build
tekton.dev/platforms: "linux/amd64,linux/s390x,linux/ppc64le,linux/arm64"
spec:
description: >-
Buildah task builds source into a container image and
then pushes it to a container registry.
Buildah Task builds source into a container image using Project Atomic's
Buildah build tool.It uses Buildah's support for building from Dockerfiles,
using its buildah bud command.This command executes the directives in the
Dockerfile to assemble a container image, then pushes that image to a
container registry.
params:
- name: IMAGE
description: Reference of the image buildah will produce.
- name: BUILDER_IMAGE
description: The location of the buildah builder image.
default: quay.io/buildah/stable:v1.30.0
- name: STORAGE_DRIVER
description: Set buildah storage driver
default: overlay
- name: DOCKERFILE
description: Path to the Dockerfile to build.
default: ./Dockerfile
- name: CONTEXT
description: Path to the directory to use as context.
default: .
- name: TLSVERIFY
description: Verify the TLS on the registry endpoint (for push/pull to a non-TLS registry)
default: "true"
- name: FORMAT
description: The format of the built container, oci or docker
default: "oci"
- name: BUILD_EXTRA_ARGS
description: Extra parameters passed for the build command when building images.
default: ""
- name: PUSH_EXTRA_ARGS
description: Extra parameters passed for the push command when pushing images.
type: string
default: ""
- name: SKIP_PUSH
description: Skip pushing the built image
default: "false"
- name: TAG
description: Image tag
default: "latest"
workspaces:
- name: source
- name: sslcertdir
optional: true
- name: dockerconfig
description: >-
An optional workspace that allows providing a .docker/config.json file
for Buildah to access the container registry.
The file should be placed at the root of the Workspace with name config.json.
optional: true
results:
- name: IMAGE_DIGEST
description: Digest of the image just built.
- name: IMAGE_URL
description: Image repository where the built image would be pushed to
steps:
- name: build
image: $(params.BUILDER_IMAGE)
workingDir: $(workspaces.source.path)
script: |
# add some extra config to search on docker.io and don't broke already well knowed images
echo 'unqualified-search-registries = ["docker.io"]' >> /etc/containers/registries.conf
[[ "$(workspaces.sslcertdir.bound)" == "true" ]] && CERT_DIR_FLAG="--cert-dir $(workspaces.sslcertdir.path)"
[[ "$(workspaces.dockerconfig.bound)" == "true" ]] && export DOCKER_CONFIG="$(workspaces.dockerconfig.path)"
buildah manifest create multiarchmanifest
buildah ${CERT_DIR_FLAG} --storage-driver=$(params.STORAGE_DRIVER) bud \
$(params.BUILD_EXTRA_ARGS) --format=$(params.FORMAT) --manifest multiarchmanifest \
--tls-verify=$(params.TLSVERIFY) --no-cache \
-f $(params.DOCKERFILE) -t $(params.IMAGE):$(params.TAG) $(params.CONTEXT)
[[ "$(params.SKIP_PUSH)" == "true" ]] && echo "Push skipped" && exit 0
# buildah ${CERT_DIR_FLAG} --storage-driver=$(params.STORAGE_DRIVER) push \
# $(params.PUSH_EXTRA_ARGS) --tls-verify=$(params.TLSVERIFY) \
# --digestfile /tmp/image-digest $(params.IMAGE):$(params.IMAGE) \
# docker://$(params.IMAGE):$(params.IMAGE)
buildah ${CERT_DIR_FLAG} --storage-driver=$(params.STORAGE_DRIVER) manifest push \
$(params.PUSH_EXTRA_ARGS) --tls-verify=$(params.TLSVERIFY) \
--digestfile /tmp/image-digest --rm multiarchmanifest \
--format=$(params.FORMAT) docker://$(params.IMAGE):$(params.TAG)
cat /tmp/image-digest | tee $(results.IMAGE_DIGEST.path)
echo -n "$(params.IMAGE)" | tee $(results.IMAGE_URL.path)
volumeMounts:
- name: varlibcontainers
mountPath: /var/lib/containers
securityContext:
privileged: true
volumes:
- name: varlibcontainers
emptyDir: {}
Creando el pipeline
Vamos ahora a definir un archivo para alimentar tekton, para que este cree un pipelinerun. En el mismo llamamos a la tarea oficial de git-clone, con parámetros especifiando el repositorio de código que queremos construir, el nombre de la imagen (incluyendo el registry), y algunos parámetros adicionales para el build, y otros para el push.
Para el build vamos a agregarle --jobs 3 --platform linux/arm,linux/arm64,linux/amd64, esto define las plataformas para las que vamos a construir la imagen, y adicionalmente le paso la cantidad de jobs en paralelo que quiero que ejecute (3, por las 3 plataformas).
Para el caso del push, el parámetro --all permite que al hacer push del manifest, también se suban las imágenes contenidas en el índice de dicho manifesto.
apiVersion: tekton.dev/v1beta1
kind: PipelineRun
metadata:
generateName: buildah-writefreely-pipeline-run-
spec:
pipelineSpec:
workspaces:
- name: shared-workspace
- name: sslcertdir
optional: true
- name: dockerconfig-ws
optional: true
tasks:
- name: fetch-repository
taskRef:
name: git-clone
workspaces:
- name: output
workspace: shared-workspace
params:
- name: url
value: https://github.com/writefreely/writefreely.git
- name: subdirectory
value: ""
- name: deleteExisting
value: "true"
- name: buildah
taskRef:
name: buildah
runAfter:
- fetch-repository
workspaces:
- name: source
workspace: shared-workspace
- name: dockerconfig
workspace: dockerconfig-ws
params:
- name: IMAGE
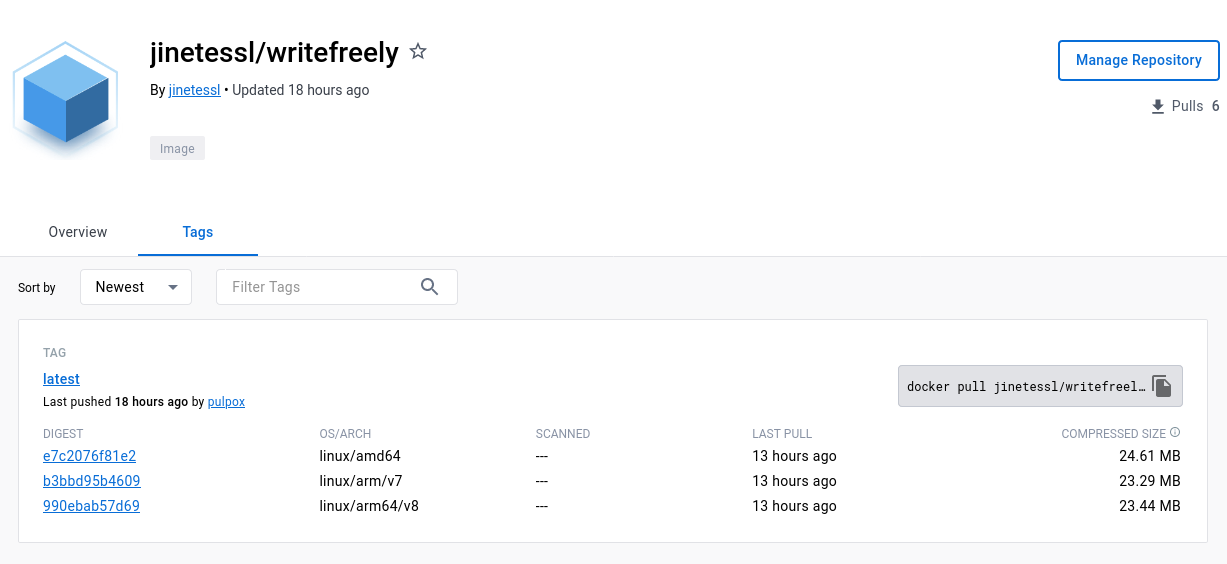
value: docker.io/jinetessl/writefreely
- name: BUILD_EXTRA_ARGS
value: --jobs 3 --platform linux/arm,linux/arm64,linux/amd64
- name: PUSH_EXTRA_ARGS
value: --all
- name: SKIP_PUSH
value: false
- name: FORMAT
value: docker
workspaces:
- name: shared-workspace
volumeClaimTemplate:
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1000Mi
- name: dockerconfig-ws
secret:
secretName: dockerconfig-secret
Adicionalmente armé un secreto con las credenciales de auth para poder subir al registro de docker las imágenes resultantes:
apiVersion: v1
kind: Secret
metadata:
name: dockerconfig-secret
stringData:
config.json: |
{
"auths": {
"docker.io": {
"auth": "XXXXXXXXXXXXXXX=="
}
}
}
Luego, tras realizar un kubectl create -f con el archivo del pipeline run, tras unos minutos tengo una imagen multiarchitectura subida en el repositorio de imágenes, un amor!